| scripts | ||
| SimpleX | ||
| submissions | ||
| templates | ||
| www | ||
| .gitignore | ||
| Dockerfile | ||
| lantern-interface.png | ||
| nginx.conf | ||
| package.xml | ||
| project.png | ||
| README.md | ||
| requirements.txt | ||
| torrc | ||
| updaterepo.sh | ||
{kind=link}
{kind=link}
Darknet Lantern Project v1.1.0

To explain the full context on why this project is relevant in the Darknet Ecosystem compared to the clearnet, check out this blogpost
For a full step-by-step tutorial on how to setup your own Darknet lantern, check out this tutorial
Feel free to join our Darknet Exploration SimpleX chatroom to talk about the project, and to let me know if you are running a Darknet Lantern instance and want to join the Darknet Webring.
What is the Darknet Lantern Project ?
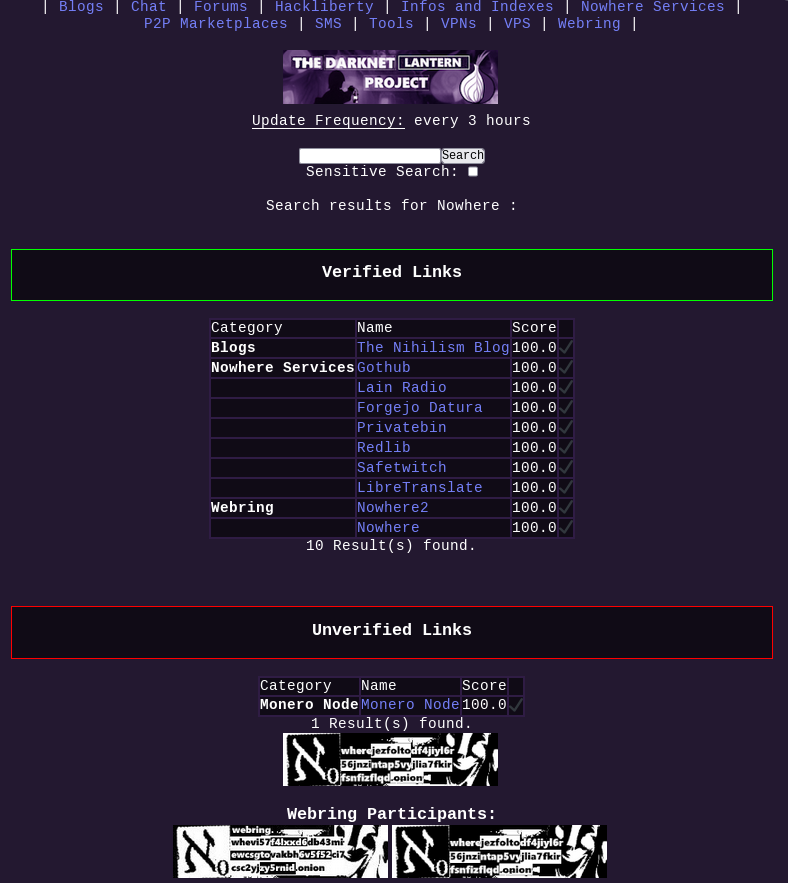
Darknet Lantern is a minimalistic Peer to Peer Decentralised Search Engine for the Darknet, that got officially released on the 1st of Febuary 2025.
Why is the Darknet Lantern relevant ?
The Darknet is fundamentally different compared to the Clearnet. Where the Clearnet is like an open city where every destination is visible from the sky, where every website is indexable and searchable using popular search engines, the Darknet is like an immense, dense dark forest where you can't see any destination from the sky.
To explore the Darknet, we need peers (like you and me) to maintain their own lists of onion links for each other, to be able to know where to go, as search engines can't automatically crawl onion websites like they do on the clearnet. The Darknet Lantern Project is a serious attempt at solving the fundamental lack of search engines on the Darknet by organising the manual peer-based work of discovering hidden services in the most efficient way, to make sure Hidden Websites can get visibility while maintaining their anonymity.
Why is the Darknet Lantern Webring relevant ?
The Darknet Lantern Project includes a Webring, as otherwise the Darknet Lanterns would remain scattered and remain hidden from each other, to participate in the webring is to exponentially increase the visibility of the Onion websites you listed, the more webring participants there are.
The more people join the Darknet Lantern Webring, the more visibility Darknet websites will be able to have over time, just like how it would be on the clearnet, while keeping the decentralisation and censorship-resistance intact. All you need is to run your own Darknet Lantern instance, and to join the Webring as a new participant.
What is the default trust model ?
When spinning up your own Darknet Lantern instance, you are automatically creating your instance folder in www/participants/yourinstancehostname.onion/ and in there you'll find a copy of the blank verified.csv, unverified.csv, and webring-participants.csv files, along with the default banner.png file.
By default, as they are in the templates/ directory, the verified.csv and unverified.csv files are empty as you shouldn't trust random links that other people are trusting, you should verify them yourself one by one, to make sure that they aren't malicious.
That is why by default, when you first setup your own lantern instance, you are not listing anything, nor trusting any links, nor trusting any webring participants. This is a safety measure by default to avoid vectors of abuse.
If you choose to do so, you can trust another webring participant, which means that in turn you'll automatically trust the links that they are trusting. But be warned that this is potentially dangerous in case if it turns out that they start to trust malicious links later down the line.
What is the lifecycle of a Lantern instance ?
At first, you have an empty Lantern, no links listed, no links trusted, no webring participants trusted either.
If you want to go your own way to explore the darknet yourself, you can start to list links yourself, into the unverified.csv file, and later on once you browse them enough to verify their authenticity, you may choose to trust them, to move them from unverified.csv to verified.csv
If you want to avoid doing the same work that other webring participants may have already done, you may choose to synchronize with their lists of links, and to add the links that you didn't list yet into your own unverified.csv file. That way you'll be able to start exploring the Darknet starting from where others left off.
After a while of adding new links and verifying them, you may choose to trust another webring participant's list of links, to automatically add their verified links into your own verified.csv file. However as stated above be warned that this is risky due to the fact that you may inadvertently trust malicious links because of that other peer.
What if there are malicious Lantern Instances ?
As stated above, it is possible that there will be malicious Lantern instances, meaning that you may have malicious peers that start to list some extremely illegal websites into their verified.csv file. This is why by default you are not trusting any Lantern webring participant, nor any links.
This is also the reason why there is a blacklist.csv file. That way, if there are any malicious keywords or links to be found, they will be immediately deleted. I for instance, refuse to list any porn sites or list any instance that lists porn websites, and i encourage you to do the same (hence the blacklist.csv file containing those words by default), as those can link to some extremely illegal content that you definitely don't want to get associated with.
Using the blacklist.csv file you can list blacklisted words, links and even links to blacklisted webring participants, that will automatically be removed if encountered by the python scripts.
Changelog + Roadmap
Previous Versions:
V0.3:
- py : option 6) Trust/Untrust/Blacklist a webring participant
- php : make a search engine prompt that only accepts [a-zA-Z.://], it must refuse every other character
- py : fix uptimecheck.py to match the new csv format
- php : if valid make it filter your own verified.csv and unverified.csv files
V0.6:
- py : option 9) cleanup all duplicates in your own unverified.csv and verified.csv
- py : option 10) perform sanity checks on all csv files (to mark them as sensitive or remove the ones that are blacklisted)
- py : option 7) Add/Remove words in the sensitive list
- py : option 8) Add/Remove words in the blacklist
V0.8:
- manual work: fit all the existing links into the current format one by one
- php/css: make the search page preety
- doc: redo the documentation for the project
v0.9
- harden the python code to make sure that the user filters out malicious inputs from other webring participants
- harden the PHP code to prevent any malicious php code from being ran from csv files even if that shouldnt be possible
V1.0.0: (01/02/2025)
- doc: finish the blogposts on why it is important, and how to setup your own instance
- release it officially to try and onboard the first webring participants
- php: find a way to display the description for each link
V1.0.1:
- py: refactor/simplify the lantern.py script wherever possible (assigned to Sovereignty)
- git: implement .gitignore to ignore www/participants, otherwise you can't do torsocks git pull without having to do a git stash
- py: since .gitignore makes it so that www/participants doesnt exist, automatically create the directory structure from www/.official_participants
- git: figured out how to have an automatically updated lantern instance via gitignore+cronjob
Current Version:
V1.0.2:
- php+css : make the css styling not ugly on mobile
- py: make sure that running option 4 automatically creates the folder for a new official webring participant and downloads the files all the same, instead of just iterating through the folders.
- py: check that banners are at the most 5MB big
- py : if an argument is passed to lantern.py, enter automation mode, and at least automate option 4, 9 and 10 (ex: python3 lantern.py 4)
- py: in option 1, upon listing new links, if the description isn't empty, consider the link as trusted, and write it verified.csv. If description is empty, write it in unverified.csv instead.
- py: merge the option 2 and 3 together to become "Trust/Untrust/Blacklist a website entry", and repurpose option 3 to become "edit existing links attributes"
Future Versions:
V1.1.0 (SimpleX chatrooms and servers uptime): (WIP)
- V1.1.0: find a way to check if the simplex invite link is still joinable or not, but without joining it every time (it should only join it ONCE) -> make it remember that this invite link equates to this chat
room name ? and then if chatroom name exists then instead of trying to join it make it look for "this chatroom has been deleted" message, if it doesn't exist then assume the chatroom is still joinable. (problem is that the bot should not join every chatroom every 3 hours just to check the uptime, it pollutes chatrooms by doing that.)
- V1.1.1: using regex alone, create the functions "isSimpleXChatroomValid", and "IsSimplexServerValid", and it should return True for ALL the different syntaxes for simplex chatroom invite links, and smp and xftp servers
- V1.1.2: uptime.py: make it able to check the uptime of 1) onion links, 2) simplex chatroom links (ONLY if it can query the simplex daemon on 127.0.0.1:3030), and 3) simplex smp and xftp servers
V1.2.0 SimpleX Crawler:
- V1.2.0: crawler.py: list all the existing simplex chatroom links in verified.csv, make the simplex bot join them via 127.0.0.1:3030 ONLY if it didn't join that chatroom yet. make sure that crawler.py is able
to know which chatroom name he's in corresponds to which invite link (either via simplex directly, or via an external simplex-crawl.csv file (columns: link (simplex:/#contact[...]), joined (y/n))
- V1.2.1: crawler.py: find a way to list (in python) the last unread messages, list them one by one, AND in each message the bot should be able to find, find every simplex link, every .onion link, and every simplex smp / xftp servers links, even if there are multiple onion / simplex links in the same message, he should be able to recognize all of them and list them locally in a crawled.csv file (for now at least, later it'll be in unverified.csv directly)
- V1.2.2: crawler.py: make the script categorize the onion links into "onion websites", the simplex chatroom invite links into "simplex chatrooms", and the simplex servers smp and xftp links into "simplex serv
ers" categories, AND in unverified.csv directly
V1.2.4+ Webring Participants expansions:
-V1.2.4: py: option 4: at the end of the synchronization phase, iterate over (your own) unverified links that do NOT have a description, and find the first description in other participants' verified.csv file to put in there, to enrich your unverified list (and skip if nobody wrote a description for it)
-V1.2.5: py: in option 4, make sure that new webring participants (that are listed from other webrings) are automatically added on your own instance aswell, in case if you trust an instance's list of webring participants (opt-in only)
-V1.2.6: py+csv: expand on the participants trust levels, add 3 columns to be filled with -1, 0 or 1 (verified.csv, blacklist.csv, webring-participants.csv) that is to customize your instance's behavior in regards to other participants
V1.3.0 Onion Crawler:
- V1.3.0: crawler.py: make the script iterate over every onion link in verified.csv, and from the page itself it should find every other a href html/php/txt file on that link directly (recursively), however it should have a limit to prevent crawling endlessly (make it configurable, for now it should crawl up to 10 sub-pages per onion site by default).
- V1.3.1: crawler.py: Make it download those webpages in a temporary folder "onioncrawling/{onionwebsitename1.onion,onionwebsitename2.onion}/{index.html,links.php}" Once a website has been crawled, make it delete the entire folder and mark it as crawled in onion-crawl.csv (columns: link (http://blahlbahadazdazaz.onion), crawled (y/n))
- V1.3.2: crawler.py: in each crawled html/php/txt file, make it find every simplex chatroom link, simplex server link, and every onion link.
- V1.3.3: crawler.py: with every link found, make sure it is properly categorized just like in v1.2.2, directly into unverified.csv
V1.3.5+ Fully automatable lantern.py + docker:
- V1.3.5: py: add an optional way to run lantern.py without any manual inputs by passing arguments (ex: python3 lantern.py 1 name desc link "description") or simply (python3 lantern.py 4) to synchronize links --> for all options! either manual lantern.py or prompt-less lantern.py with arguments
- V1.3.6: docker: figure out how to dockerize the darknet lantern project while maintaining the onion-only requirement (c0mmando is on it, will merge it when he finishes)
V1.4.0+ PGP support:
- csv+php+py: implement PGP support to list public pgp keys for verified websites
- csv+php: figure out how to expand the software to include simplex chatrooms (maybe add another column ?)
- py: simplex chatrooms, figure out a way to check their uptime aswell (if the invite link is still valid or not)
V1.5.0+ I2P support:
- add i2p support for eepsites (hopefully by then the blogposts on i2p will be written)
How can I setup my own Darknet Lantern ?
For the full step-by-step tutorial on how to setup your own Darknet lantern (with the screenshots), check out this tutorial
How can I officially get listed as a webring participant on the git repository ?
In short the requirement is that you should have the core functionnality of listing the links you didn't verify yet, listing the links you verified, including some onion links listed that i didn't list yet, and that are not porn-related. If you have a working lantern instance with some new onion links, ping me directly on SimpleX to get your lantern instance listed on my own 2 instances, and if after checking it is OK to get added (meaning it is at least a little noob friendly and you don't have any porn links listed there) i'll push a git commit with the updated files.
Sidenote: you are free to fork the project, and change how the front-end looks to customize it, but the CSV format (especially the columns order and their titles, and the values format) and the paths need to remain the same (ex: http://URL.onion/participants/URL.onion/verified.csv)
If you want to run your own webring yourself, simply fork the git repository on your own forgejo instance, and federate with other darknet lantern instances with your own different set of rules.
How can I officially get listed as a trusted webring participant on the git repository ?
I officially won't officially trust any webring participant. I prefer to manually verify each new link i synchronize my instance with, if i find any to be interesting. Instead i will leave "trusting other webring instances" up to whoever wants to run that risk themselves. I prefer to only manually approve new webring participants on my own, because if i try to let it loose and try to automatically trust random webring participants, many blacklisted links may end up getting listed inadvertently.
LICENSE
There are no rights reserved, the entire project is public domain (Creative Commons 0 license)
LEGAL DISCLAIMER
Across the entirety of all Darknet Lantern instances and all of the lists of links listed therein, the sole purpose of providing links to various darknet websites is strictly for informative and educative purposes. The administrator(s) of this darknet lantern instance decline any and all responsibility regarding any physical, digital and psychological damage caused by any of the listed websites, as the responsibility of such acts remain with the perpetrating third-party. By using this service, you permanently, irrevocably, and world-widely agree that the administrators of any darknet lantern instances aren't to be held responsible in any way for anything that another website ever did or will ever do, even if the link to that third-party website has been, is, or will ever be listed on any darknet lantern instance.
OLD stuff
WARNING, BREAKING CHANGES FROM V1.0.0 TO V1.0.1, HERE IS HOW YOU CAN UPGRADE: (after that upgrade, you'll be able to automate the updates of lantern via a cronjob that runs a git pull in the root project directory, without having to discard changes made in www/participants/, thanks to the new .gitignore)
cd /srv/darknet-lantern
#backup your participants directory:
cp -r www/partcipants /tmp/participants
#abandon changes in the git directory
git stash
#update the git repo by doing a git pull
torsocks git pull
#reimport your csv files:
cp -r /tmp/participants www/participants
#make sure that your csv files no longer have v or x as status/sensitive booleans, by running option 10:
python3 scripts/lantern.py
Select an option? (0-10): 10